Introdução à análise de algoritmos¶
Um algoritmo pode ser definido como uma sequência de passos usada para resolver algum problema. Naturalmente, em computação, estamos mais interessados em problemas que possam ser abstraídos usando matemática e algoritmos para esses problemas que sejam precisos na definição de cada passo e passíveis de reprodução por um computador (ou modelo de computação). Sendo assim, podemos estabelecer a seguinte relação entre o que é prático e o que é abstrato no estudo da resolução de problemas:
Programa ~ Linguagem de programação
Computador físico ~ Algoritmo
Pseudocódigo ~ Computador abstrato (ou modelo de computação)
Nosso objetivo é estudar algoritmos do ponto de vista abstrato (segunda coluna acima). A primeira etapa, portanto, é formalizar bem um problema para que não se tenha dúvidas com relação ao que é dado como entrada e o que se espera como resultado (saída). Por exemplo, o problema de ordenar um conjunto de números inteiros em um arranjo pode ser formalizado da seguinte forma:
Entrada: sequência de números inteiros organizados em um arranjo
Saída: permutação tal que
Modelo de computação e conceitos de análise¶
O primeiro requisito ao se trabalhar com algoritmos é ser capaz de analisá-los, isto é, precisamos ser capazes de determinar certas características do algoritmo antes mesmo de implementá-lo e executá-lo na prática. Por exemplo, é muito comum que estejamos interessados em algoritmos eficientes. Precisamos, portanto, estabelecer como será o computador abstrato ao qual o algoritmo estudado se refere. No estudo de algoritmos vamos adotar um modelo de computação abstrata que reflete características muito comuns de arquiteturas computacionais contemporâneas: o modelo RAM – Random Access Machine. As seguintes características estão presentes em algoritmos projetados para o modelo RAM:
As instruções dos algoritmos são executadas sempre sequencialmente, sem nenhum tipo de con- corrência ou paralelismo;
Vamos assumir que os dados manipulados pelos algoritmos são organizados em uma memória de acesso aleatório e organizada em palavras;
Tipos de dados: inteiros, ponto flutuante, arranjos de palavras (sequência de inteiros ou ponto flutuante), qualquer outra estrutura de dados derivada;
Operações aritméticas em geral:
+, −, ÷, ×, %, etc.;Controle:
while, for, do .. while, return,subrotinas/funções, condicionais (if, else), operadores de comparação (==, <, >, etc.);Atribuições de variáveis são representadas como
=.
Pseudocódigo no modelo RAM.¶
Vamos ver um exemplo de algoritmo para o problema de contar quantas vezes um
número inteiro n ocorre em um arranjo de inteiros v. Formalmente, entrada:
inteiro n e arranjo de inteiros v; saída: inteiro c representando o número
de ocorrências de n em v. O tamanho de v é representado nesse exemplo como
|v|:
conta-ocorrencias(n, v)
c = 0
for i = 1 to |v|
if v[i] == n
c = c+1
return cDimensões de análise¶
Diferentes instâncias podem demandar diferentes níveis de dificuldade para a execução do algoritmo. Esperamos que, seja em uma máquina abstrata ou não, cada problema é passível de encontrar instâncias fáceis (entradas fáceis) ou instâncias mais difíceis (entradas mais difíceis). Por exemplo, para o problema de contar as ocorrências de um número no arranjo não é razoável assumir que o mesmo algoritmo irá se comportar da mesma forma para um arranjo de 10 elementos em comparação a um arranjo de 107 elementos. Por esse motivo, vamos sempre estudar algoritmos em função do tamanho da entrada que lhe é apresentada. Com isso, temos nosso principal objetivo em análise de algoritmos: para um algoritmo, determinar seu consumo de tempo e/ou espaço frente a instâncias cada vez maiores na entrada.
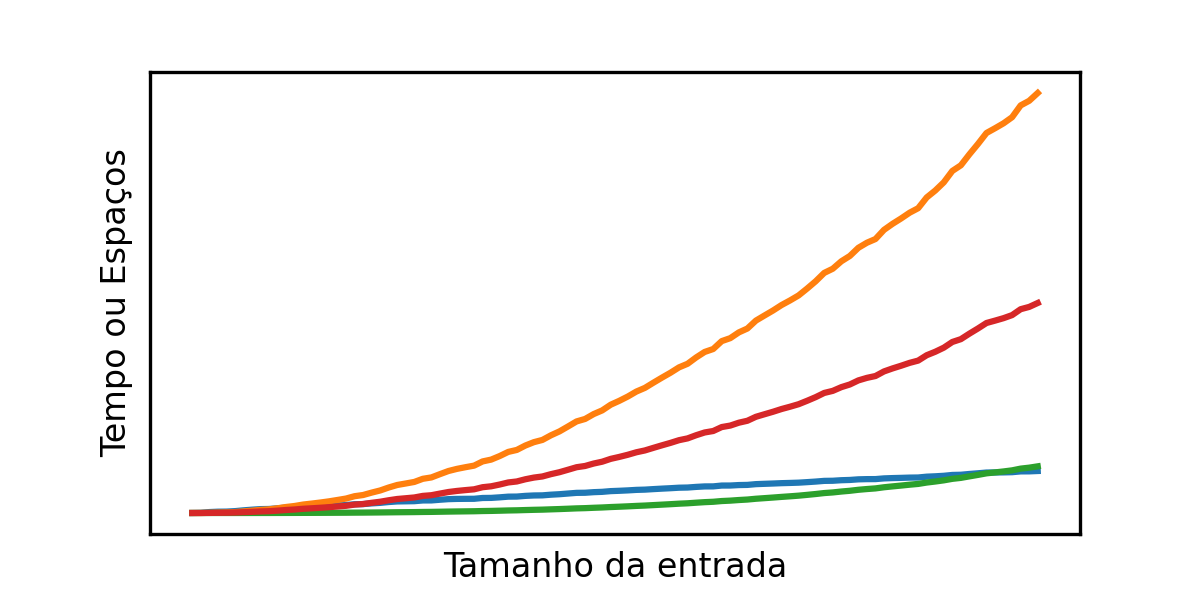
As duas noções de dificuldade para um computador abstrato que estamos interessados são:
Tempo: quantas operações básicas um algoritmo executa para uma dada instância do problema. Nesse caso, ao invés de medir tempo de relógio, nós vamos contar quantas operações um algoritmo executa.
Espaço: quanto de espaço (palavras do RAM) além da entrada o algoritmo utiliza em função também do tamanho da instância de entrada.
Chamamos portanto de operação básica aquilo que pretendemos medir em um algoritmo. Na prática, poderíamos medir tanto operações específicas quanto conjuntos de operações de interesse. Para facilitar a discussão, iremos focar em análises que consideram apenas uma operação básica como alvo de estudo. Essa escolha é feita por quem analisa o algoritmo, mas por exemplo: (a) para um problema de ordenar números em um arranjo pode ser natural pensar que as operações que são mais importantes para determinar a ordem entre os elementos são as operações que comparam dois elementos do arranjo: , por exemplo; (b) para um problema matemático de encontrar o máximo divisor comum entre dois números pode ser uma boa prática escolher operações aritméticas (possivelmente o resto da divisão, pensando na estratégia de Euler) como operação básica. Portanto, não existe regra mas existem boas práticas.
Contexto de análise¶
O pior caso representa instâncias para o problema que fazem o algoritmo trabalhar ao máximo: usar o máximo de espaço ou executar o máximo de operações básicas possível. O melhor caso é o contrário, indicando cenários otimistas para o algoritmo. Finalmente, o caso médio representa os casos em que o algoritmo trabalha de acordo com esperado na média, para isso sendo necessário assumir algumas características da entrada (por exemplo, independência e instâncias de entrada igualmente prováveis).
Corretude de algoritmos¶
Para ilustrar como identificar algoritmos corretos, vamos usar como exemplo um algoritmo famoso de ordenação:
insertion-sort(a) // assuma n como sendo o tamanho de a
for i = 2 to n
elem = a[i]
j = i − 1
while j >= 1 and elem < a[j]
a[j+1] = a[j]
j = j − 1
a[j+1] = elemO algoritmo segue o princípio de organização de cartas de um baralho na mão de
um jogador: sempre inserimos uma nova carta em sua posição correta na mão. Dessa
forma, a mão sempre contém um subconjunto de cartas já ordenadas (nesse caso,
usaremos inteiros para ilustrar). Para verificar a corretude do insertion-sort
utilizaremos uma metodologia que lembra uma indução matemática (sendo bem
sincero, É uma indução matemática adaptada ao contexto de algoritmos). Vejamos:
Se um algoritmo não possui nenhum laço de repetição, sua corretude é de fácil verificação através da inspeção exaustiva de cada uma de suas operações, sequencialmente.
Vamos nos concentrar, portanto, em cenários em que o algoritmo contém laços de repetição que alteram seu comportamento de acordo com o tamanho da entrada.
Para esse último caso, a técnica indutiva utilizada é denominada “invariante de loop”, e consiste da verificação de três etapas:
Inicialização: mostramos que alguma propriedade do algoritmo é garantida antes da entrada no loop.
Manutenção: mostramos que, antes de iniciar a próxima iteração do loop, a propriedade continua sendo garantida.
Terminação: mostramos que ao final do loop, a propriedade continua sendo garantida e que, desse fato, concluímos que o algoritmo é correto.
Naturalmente, essa dita propriedade deve ser algo relacionado ao que o algoritmo
de propõe a resolver. No caso da ordenação, ordenar alguns números. Vamos
aplicar a técnica para o insertion-sort. A propriedade pertinente é: “a todo
momento do algoritmo, temos que alguns números já estão ordenados () e esses números são os mesmos que, originalmente, se encontravam nas
mesmas posições ”. Inicialização: antes do loop, , e
por isso o arranjp está ordenado trivialmente. Manutenção: antes
de iniciar uma próxima iteração, temos que é um subarranjo
ordenado. Em uma iteração , o algoritmo posiciona em sua posição
correta/ordenada em realizando o deslocamento de elementos
maiores enquanto for necessário. Assim, ao final, da iteração i temos os mesmos
elementos mas ordenados. Terminação: ao final da última
iteração, . Como está ordenado, então também estará. Qualquer algoritmo com laços pode ser
verificado formalmente utilizando invariantes e se o algo- ritmo contiver vários
laços, um conjunto de invariantes pode ser usado para garantir sua corretude
globalmente.
Notações assintóticas¶
Quando analisamos um algoritmo, tipicamente queremos encontrar uma função matemática que representa a complexidade de tempo ou espaço sob algumas condições (como o contexto de análise, por exemplo). Na prática, essas funções podem ser bem diversas em termos de constantes e termos. Por exemplo, poderia ser uma função que representa o crescimento do número de operações do algoritmo à medida que o tamanho da entrada cresce (). Esse polinômio tem grau 2, apesar de todos os coeficientes e termos da função, assim como é outro polinômio de grau 2. O interessante é que o fato de ser um polinômio de grau 2, independentemente dos coeficientes e termos, já nos remete ao formato da curva dessa função: uma parábola. Como veremos, as notações assintóticas nos ajudam justamente a categorizar funções cujas ordens de crescimento (ou formatos de curva) são equivalentes.
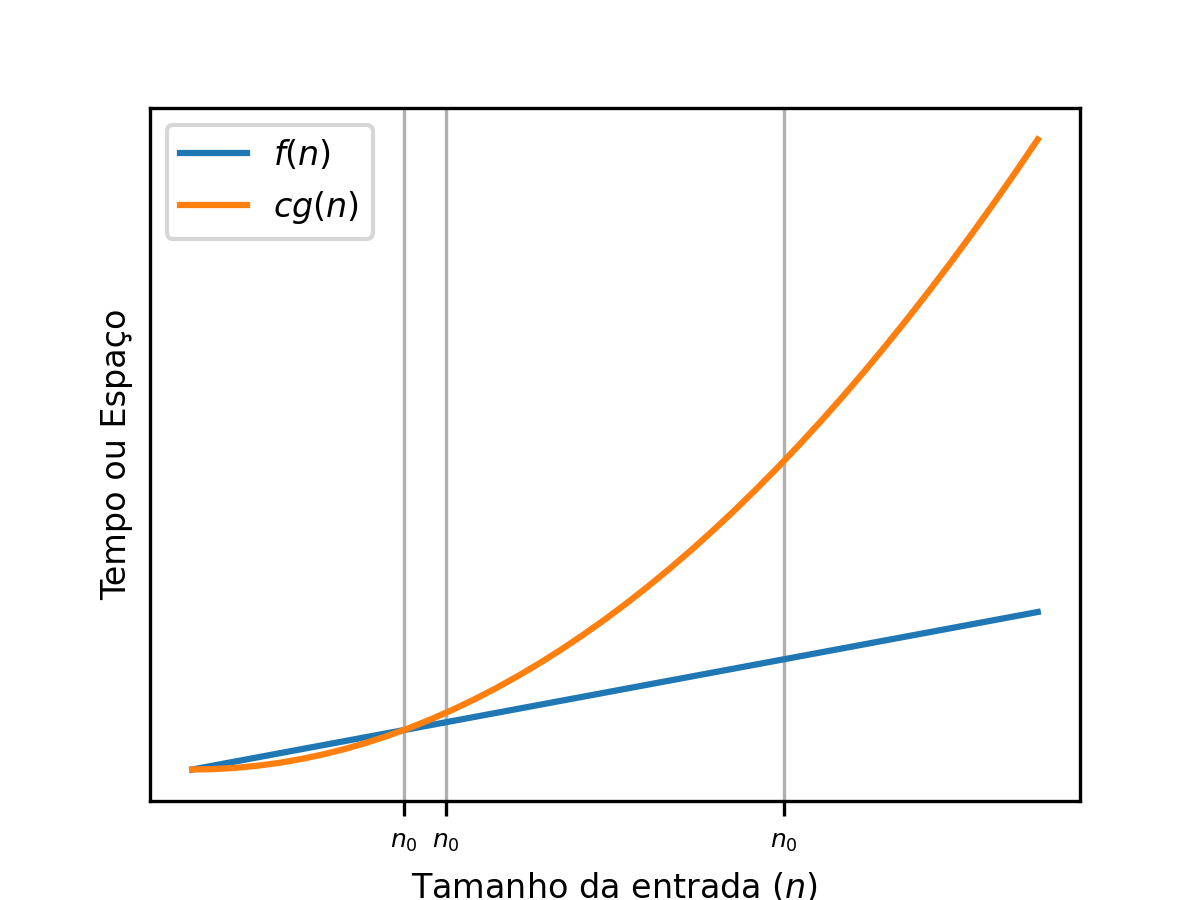
Big-Oh ou : um limite superior para o crescimento de funções¶
Esta notação é utilizada para estabelecer um limite superior para o crescimento de funções (nesse caso, ). Dessa forma, pois nada cresce mais do que o termo quadrático quando . Da mesma forma, , já que uma parábola sempre irá ultrapassar uma reta a partir de algum momento. Formalmente, sse: existirem constantes e () tais que: para todo .
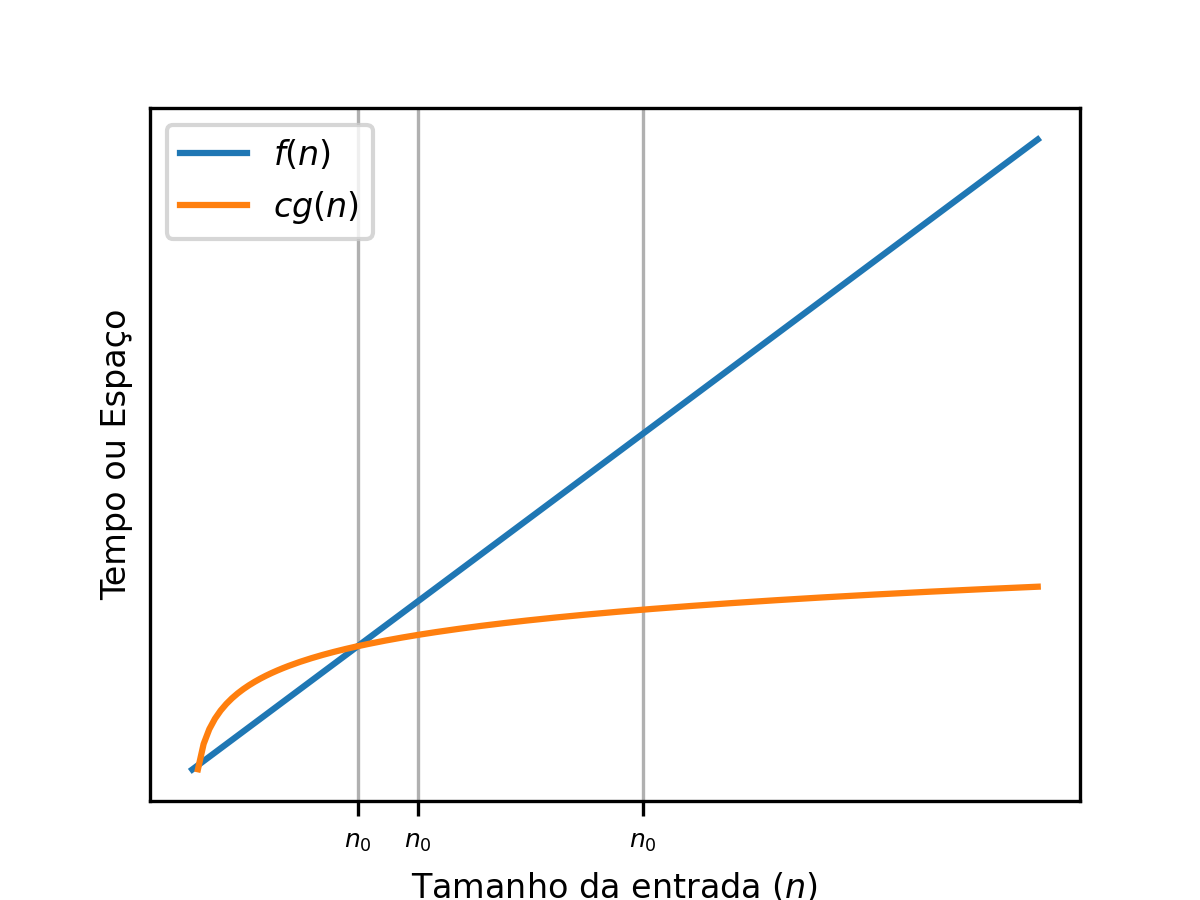
Big-Omega ou : um limite inferior para o crescimento de funções¶
É utilizada para representar limites inferiores de funções. Assim, quando , e , mas . Veja a seguir uma ilustraçao que indica isso: Formalmente, sse: Existirem constantes e () tais que: para todo .
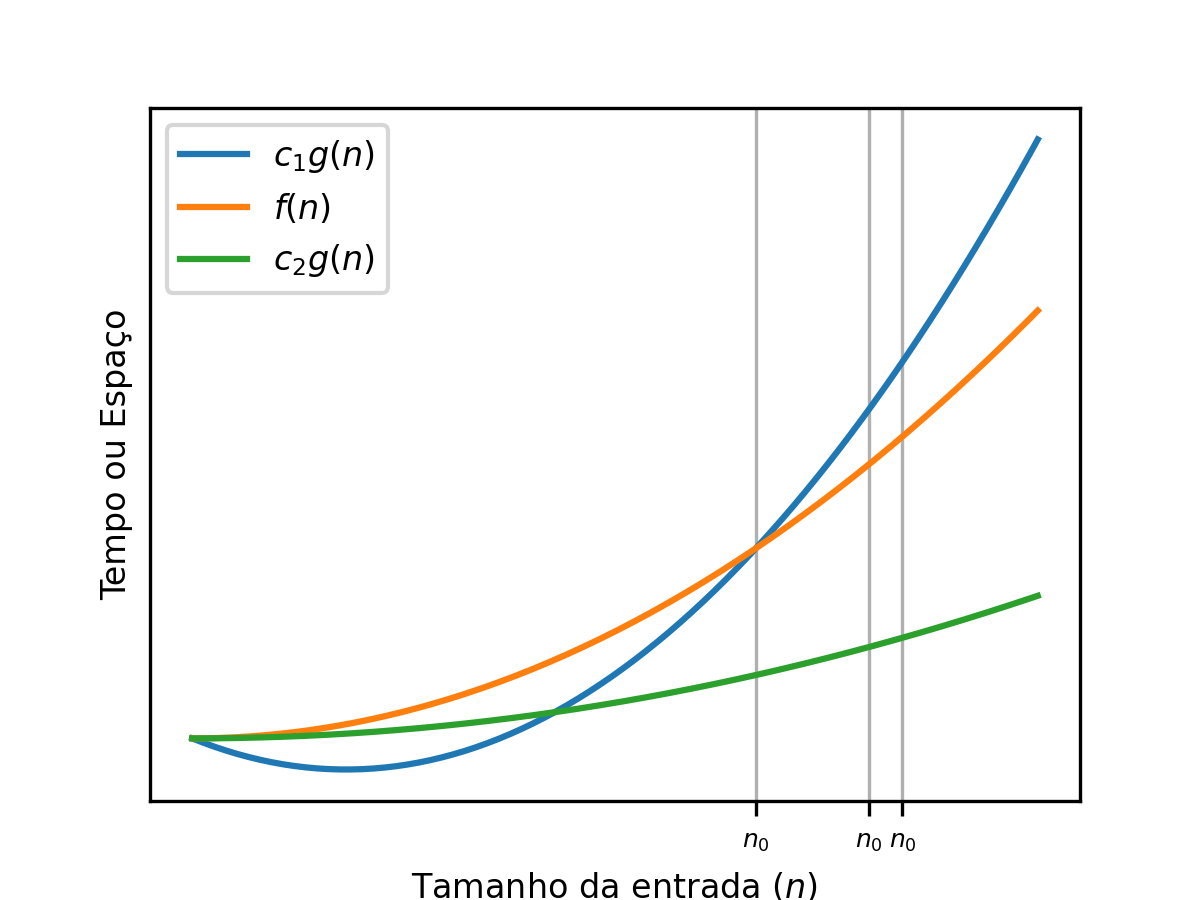
Big-Theta ou : um limite justo para o crescimento de funções¶
Um limite justo é usado para representar os casos em que uma função pode ser limitada tanto inferiormente () quanto superiormente () por uma outra função. De maneira informal, dizer que equivale a afirmar que ambas as funções possuem exatamente a mesma ordem de crescimento assintótico. Formalmente, sse e .
Analisando algoritmos iterativos¶
Procedimento padrão para analisar algoritmos iterativos:
Definir se é uma análise de tempo ou espaço
Caso seja tempo:
a. Definir a operação básica (ou conjunto de operações básicas)
b. Definir o contexto de análise (pior, melhor ou caso médio)
c. Determinar a função de complexidade: quantidade de operações básicas em função do tamanho da entrada e considerando o contexto de análise d. Fornecer e provar um limite assintótico para a função de complexidade (O, Ω ou Θ)
Caso seja espaço:
a. Definir o contexto de análise (pior, melhor ou caso médio)
b. Determinar a função de complexidade: identificar, considerando o contexto, quantas palavras do modelo RAM são necessárias para o algoritmo em função do tamanho da entrada.
c. Fornecer e provar um limite assintótico para a função de complexidade (O, Ω ou Θ)
Analisando algoritmos recursivos¶
O procedimento padrão para analisar algoritmos recursivos é semelhante ao dos algoritmos iterativos, mas com algumas diferenças importantes:
A função de complexidade é inicialmente expressa como uma recorrência , que indica o caso base e o caso recursivo do custo associado ao algoritmo.
A função de complexidade é obtida a partir da solução da recorrência, isto é, encontrar uma função fechada para a definição recursiva.
Dessa forma, apenas os passos 2c e 3b são diferentes do procedimento para análise de algoritmos iterativos.
No próximo capítulo, serão abordadas as formas de se resolver recorrências, juntamente com o paradigma de divisão e conquista.