Ordenação bolha (bubblesort)¶
A ideia do bubblesort é realizar sucessivas trocas de elementos adjacentes que estejam fora de ordem até que todos estejam garantidamente em sua posição correta ordenada. É importante observar que a quantidade máxima de vezes em que um elemento do arranjo se encontre fora de ordem com seu adjacente é , sendo o tamanho do arranjo. Em outras palavras, ele deveria ser trocado com todos os outros elementos do arranjo que não ele próprio e por isso, o laço mais externo do algoritmo é executado vezes. Na primeira iteração, o menor elemento é levado à primeira posição. Na segunda iteração, o segundo menor é levado à segunda posição, e assim por diante.
bubble-sort(a) // n = |a|
for i=1 to n-1
for j=n down to i+1
if a[j] < a[j-1]
swap(a, j, j-1)Complexidade de tempo (pior caso e melhor caso): , pois a operação de comparação entre elementos acontece sem restrições dentro dos dois laços aninhados.
Complexidade de espaço (pior caso e melhor caso): , pois usamos apenas uma quantidade constante de memória para variáveis auxiliares além da memória fornecida na entrada.
Ordenação por inserção (insertionsort)¶
A ideia do insertion sort é começar com um subarranjo ordenado e adicionar elemento a elemento em sua posição correta no nesse subarranho ordenado. Ao final, o subarranjo ordenado vai conter todos os elementos do arranjo e portanto, o problema estará resolvido. A analogia para este método é a ordenação de cartas de baralho na mão: a cada carta retirada do monte é posicionado na ordem, em sua posição correta na sequência em construção.
insertion-sort(a) // assuma n como sendo o tamanho de a
for i = 2 to n
elem = a[i]
j = i - 1
while j >= 1 and elem < a[j]
a[j+1] = a[j]
j = j - 1
a[j+1] = elemComplexidade de tempo (pior caso): , sendo que isso acontece quando a comparação
elem < a[j]acontece todas as vezes possíveis a cada iteração do laço exterior, isto é, vezes.Complexidade de tempo (melhor caso): , sendo que isso acontece quando a comparação
elem < a[j]é feita apenas uma vez a cada iteração do laço exterior, isto é, quando o arranjo já se encontrar ordenado.Complexidade de espaço (pior caso e melhor caso): , pois usamos apenas uma quantidade constante de memória para variáveis auxiliares além da memória fornecida na entrada.
Ordenação por intercalação (mergesort)¶
O merge sort é um algoritmo de divisão e conquista que utiliza intercalação para combinar subarranjos ordenados dois a dois em arranjos maiores também ordenados. O processo de intercalação (merge) pode ser feito de forma eficiente em tempo linear partindo da premissa que os arranjos de entrada são fornecidos ordenados.
merge(left, right, a) // |left| = n ; |right| = m ; |a| = n + m
i = 1; j = 1; k = 1
while i <= n and j <= m
if left[i] < right[j]
a[k] = left[i]; i = i + 1
else
a[k] = right[j]; j = j + 1
k = k + 1
while i <= n
a[k] = left[i]; i = i + 1; k = k + 1
while j <= m
a[k] = right[j]; j = j + 1; k = k + 1merge-sort(a) // |a| = n
if n == 1 or n == 0 return
mid = floor(n / 2)
left = a[1 ... mid]
right = a[mid+1 ... n]
merge-sort(left)
merge-sort(right)
merge(left, right, a)Complexidade de tempo (pior caso e melhor caso): A recorrência desse algoritmo é a seguinte:
Pois resolvemos dois subproblemas de metade do tamanho original (), representando o custo de conquistar; gastamos para dividir com o problema com uma operação aritmética simples; e gastamos para criar os dois arranjos intermediários das metades e para intercalá-los (merge).
Complexidade de espaço (pior caso e melhor caso): , por conta dos dois arranjos das metades que precisam ser alocados para as chamadas recursivas.
Quicksort¶
particiona(a, l, r) // a indexado de l a r, inclusive
pivot = a[r]
i = l - 1
for j = 1 to r-1
if a[j] <= pivot
i = i + 1
swap(a, j, i) // troca elementos de posição
swap(a, i+1, r)
return i+1quicksort(a, l, r) // a indexado de l a r, inclusive
if l >= r return
p = particiona(a, l, r)
quicksort(a, l, p - 1)
quicksort(a, p + 1, r)Complexidade de tempo (pior caso): , representando duas partições desbalanceadas, uma com zero elementos e uma com todo o restante de elementos menos o pivot. Se isso acontecer, a cada chamada o problema diminui de apenas uma unidade (o pivot).
Complexidade de tempo (melhor caso): , representando um particionamento ideal a cada chamada recursiva, isto é, totalmente balanceado.
Complexidade de espaço: , pois o algoritmo é in-place.
Heapsort¶
O algoritmo se baseia em uma estrutura de dados chamada heap, usada para
garantir o acesso ao maior (ou menor) elemento com custo constante. O heap
máximo pode ser visualizado como uma árvore binária de chaves que mantém a
seguinte propriedade: todo nó filho da árvore é menor ou igual ao seu pai. Uma
característica importante dessas estruturas heap é que se houver alguma violação
de sua propriedade em um único nó, é possível reorganizar seus itens em um heap
válido em tempo – isso é feito através do procedimento
max-heapify.
left(i)
return 2*i
right(i)
return 2*i + 1max-heapify(a, i)
l = left(i); r = right(i)
if l <= a.heapsize and a[l] > a[i]
largest = l
else
largest = i
if r <= a.heapsize and a[r] > a[largest]
largest = r
if not (largest = i)
swap(a, largest, i)
max-heapify(a, largest)build-max-heap(a)
a.heapsize = a.length
for i=a.length/2 down to 1
max-heapify(a, i)heap-sort(a)
build-max-heap(a)
for i=a.heapsize down to 2
swap(a, 1, i)
a.heapsize = a.heapsize - 1
max-heapify(a, 1)Complexidade de tempo (pior caso): . A complexidade do algoritmo
max-heapifyé da ordem da altura do nó na posição . O procedimentobuild-max-heaprealiza chamadas aomax-heapifyna metade dos nós (a segunda metade sempre serão folhas da árvore binária e portanto, já são heaps válidos!). Por ser uma árvore binária, temos mais nós com altura pequena do que nós com altura grande e portanto, ao somar os custos demax-heapifypara cada nó na metade inferior do arranjo, temos um somatório que descresce muito rápido em seus termos, levando a um custo linear . Juntando tudo, o procedimento heap sort realiza chamadas ao procedimentomax-heapifye esse custo domina a chamada inicial linear da construção do heap.Complexidade de espaço: , pois o algoritmo é in-place.
Ordenação em tempo linear¶
Uma abordagem tradicional em estudo de algoritmos é classificá-los em classes de complexidade assintótica, permitindo a comparação direta entre algoritmos. Uma segunda abordagem complementar é ser capaz de afirmar algo sobre a complexidade de um problema frente a um modelo de computação. Em outras palavras, podemos querer responder o seguinte:
“Dados um modelo de computação e um problema, qual é a complexidade mínima que um algoritmo precisa ter para ser correto em solucionar o problema?”
Veja que a resposta para essa pergunta seria uma afirmação muito mais forte do que dizer algo sobre a complexidade de algoritmos isoladamente, já que ela envolve considerar todos os infinitos e possíveis algoritmos que solucionam um problema. Chamamos isso de limites inferiores para problemas.
Limite inferior para ordenação¶
Se considerarmos um modelo de computação baseado em operações de comparação, podemos ilustrar a operação de qualquer algoritmo de ordenação através de uma árvore de decisão. Uma árvore de decisão é uma árvore binária onde cada nó representa uma comparação feita em algum momento no algoritmo (operação) e as arestas representam as respostas para essas comparações: verdadeiro ou falso. Dessa forma, um caminho da raíz até uma das folhas dessa árvore representa uma execução do algoritmo, ou o conjunto de testes/decisões que o algoritmo toma dependendo da entrada. Veja um exemplo para um algoritmo que ordena três letras:
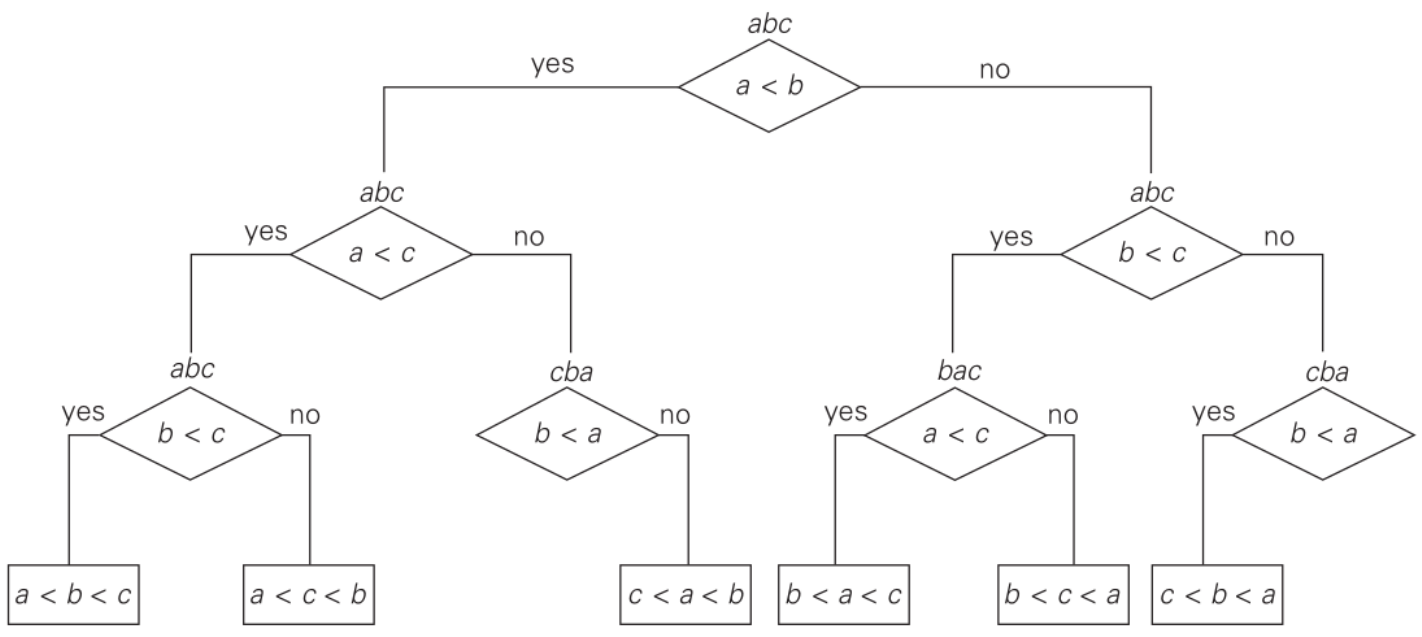
Podemos generalizar para o problema de ordenação de um arranjo qualquer e vamos constatar que as folhas dessa árvore binária de decisão representam possíveis saídas de um algoritmo de ordenação, isto é: , pois cada permutação do arranjo precisa ter uma folha representante, senão o algoritmo seria incorreto! A altura dessa árvore representa exatamente o número de comparações (operações) realizadas em alguma execução, seja lá qual for o algoritmo. Dessa forma, se estimarmos a altura da árvore estaremos na verdade estimando o custo mínimo que um algoritmo de ordenação precisa ter para resolver o problema corretamente para qualquer instância de entrada. Sabemos também que a altura de uma árvore binária com folhas é, pelo menos, :
Conclusão: Não pode existir nenhum algoritmo para o modelo de computação baseado em comparações que tenha um custo assintótico melhor do que .
Ordenação por contagem (countingsort)¶
A primeira etapa é alocar um arranjo de tamanho que será usado para contar o número de ocorrências de cada elemento. Com isso, vamos acumular nas posições de de maneira que contenha o número de elementos , dessa forma podemos identificar para cada elemento de a posição exata que ele deve ocupar no arranjo ordenado . Com iremos então, para cada elemento de em sua ordem inversa, colocá-lo na sua posição correta em . Toda vez que adicionamos um novo elemento em sua posição correta precisamos decrementar a quantidade de elementos menores ou iguais àquele, para que repetições de um mesmo elemento possam ser posicionadas em suas posições corretas também.
counting-sort(A, B, k)
C = "novo arranjo com k + 1 posições: 0 ... k"
for i = 0 to k
C[i] = 0
for j = 1 to A.length
C[A[j]] = C[A[j]] + 1
for i = 1 to k
C[i] = C[i] + C[i - 1]
for j = A.length down to 1
B[C[A[j]]] = A[j]
C[A[j]] = C[A[j]] - 1Radix sort¶
radix-sort(A) // A: array of non-negative integers
max_val = max(A)
exp = 1
B = new array of length |A|
while max_val / exp > 0
counting-sort-by-digit(A, B, 9, exp)
copy B into A
exp = exp * 10
return A
counting-sort-by-digit(A, B, k, exp) // stable sort by digit at exponent exp, digits in 0..k
// k = 9 for base 10
C = new array[0..k] filled with 0
for j = 1 to |A|
digit = (A[j] / exp) % (k + 1)
C[digit] = C[digit] + 1
for i = 1 to k
C[i] = C[i] + C[i - 1]
for j = |A| down to 1 // iterate backwards to preserve stability
digit = (A[j] / exp) % (k + 1)
B[C[digit]] = A[j]
C[digit] = C[digit] - 1Bucket sort¶
TODO: REVISAR
bucket-sort(A, k) // A: array of n elements in [0, 1)
n = |A|
B = new array of n empty lists
M = 1 + 'maximum key in A' // optional, for scaling
for i = 1 to k
index = floor(k * A[i] / M) // scale A[i] to [0, k)
append A[i] to B[index]
for i = 0 to n - 1
insertion-sort(B[i]) // or any other sorting algorithm
result = new array of length n
j = 1
for i = 0 to k
for each element in B[i]
result[j] = element
j = j + 1
return result